Dynamic BigQuery Dataflow Pipeline
Overview
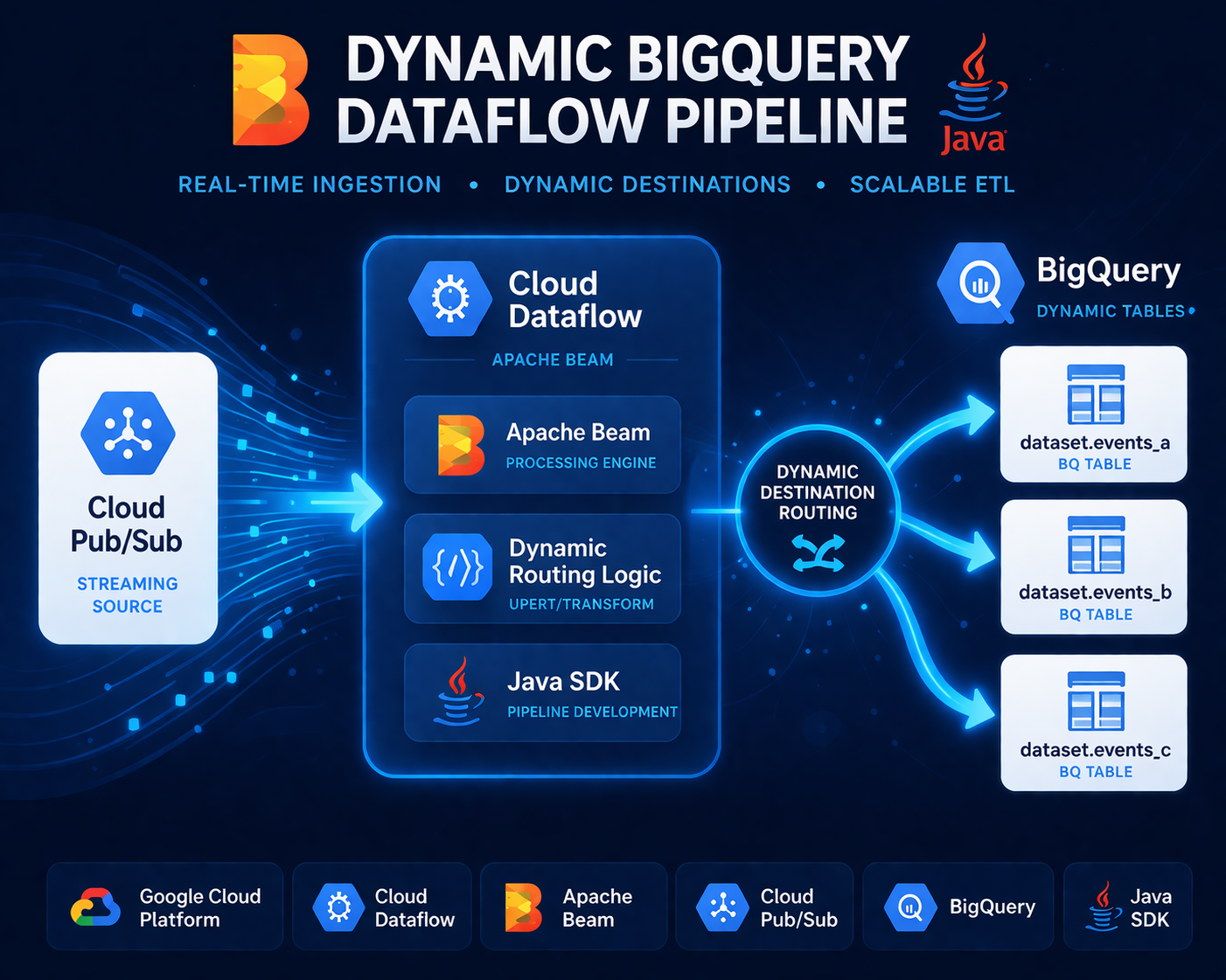
This project is a production-grade, serverless streaming data pipeline built with Apache Beam (Java SDK) and deployed on Google Cloud Dataflow. It continuously ingests JSON event data from a Google Cloud Pub/Sub subscription and dynamically routes each message to the appropriate BigQuery table within a target dataset — all in real time, without human intervention or pipeline restarts.
The core problem it solves is a common one in event-driven architectures: a single data stream carries events of multiple types, each needing to land in its own destination table. Rather than running a separate pipeline per event type, this pipeline handles all routing logic internally, driven entirely by the content of each message. The result is a single, maintainable, auto-scaling pipeline that adapts to the shape of incoming data.
A built-in dead-letter mechanism routes malformed or invalid messages to a separate Pub/Sub topic instead of crashing the pipeline, ensuring fault tolerance and preserving data for reprocessing.
Architecture
Pub/Sub Subscription
│
▼
┌───────────────────────────────────────────┐
│ Apache Beam / Dataflow │
│ │
│ Read Message → Parse → Validate │
│ │ │
│ ┌──────────────┴──────────┐ │
│ ▼ ▼ │
│ Valid Messages Invalid Messages
│ │ │ │
│ Dynamic Table Routing Dead-letter │
│ (table name from message) Pub/Sub Topic│
│ │ │
└──────────────┼────────────────────────────┘
▼
BigQuery Dataset
┌──────┬──────┬──────┐
│tbl_A │tbl_B │tbl_C │ ...
└──────┴──────┴──────┘
The pipeline is fully managed by Dataflow's Streaming Engine, which offloads execution state management from worker VMs to Google's backend, reducing resource consumption and improving throughput. It is configured with throughput-based autoscaling, scaling between 1 and 5 workers in response to Pub/Sub backlog.
The project supports two deployment models:
- Classic Dataflow Template — compiled and stored in GCS for reuse
- Dataflow Flex Template — packaged as a shaded (uber) JAR, containerised via Docker using a base Java 11 image, and stored as a versioned template in GCS. This is the more modern, recommended approach.
The pipeline also supports in-flight updates — the running job can be updated with new code by validating the job graph first (--additional-experiments=graph_validate_only) and then executing a streaming update, with no downtime.
Key Decisions
Dynamic BigQuery destinations over static table writes. Rather than hard-coding destination tables, the pipeline derives the target table name from each Pub/Sub message at runtime. This makes the pipeline resilient to new event types — adding a new event category requires no code change, just a new table in BigQuery.
toRemovePrefix flag for table name normalisation. A configurable boolean parameter allows the pipeline to strip a common prefix from derived table names. This decouples the naming convention used in the upstream event system from the naming convention in BigQuery, without hardcoding transformation logic.
Dead-letter queue via Pub/Sub. Invalid or unparseable messages are forwarded to a separate Pub/Sub topic rather than discarded or used to fail the job. This enables downstream reprocessing, auditing, and alerting without impacting the main pipeline's availability.
Flex Templates over Classic Templates. The project evolved to use Flex Templates, which are packaged as Docker images rather than staged pipeline graphs. This removes the ValueProvider constraints of Classic Templates, allowing richer runtime parameterisation and compatibility with Runner V2.
Streaming Engine + Runner V2. Both are explicitly enabled at deployment. Streaming Engine reduces per-worker memory and CPU overhead by moving windowing/state operations into the Dataflow service layer, while Runner V2 provides improved performance and reliability for streaming workloads.
Maven with a shaded JAR build. Dependencies are bundled into a single fat JAR (-shaded.jar), eliminating classpath conflicts at deployment time. The build separates DirectRunner and DataflowRunner profiles, making local testing straightforward before deploying to GCP.
Structured, configurable logging. Worker-level logging is configurable via a properties file and can be overridden per package at runtime (--workerLogLevelOverrides), keeping production logs clean while enabling targeted DEBUG output during development.